■ 이진분류는 머신러닝에서 데이터를 2 개의 클래스로 나누는 작업을 의미
이 과정에서 각 데이터 포인트가 특정 클래스에 속하는지 여부를 예측합니다.
일반적으로 " True" 클래스와, False 클래스로 나누어진다.
이진분류 예시
스팸 이메일 분류 : 이메일이 스팸인지 아닌지를 분류
질변진단 : 환자가 특정 질병에 걸렸는지 여부를 판단
고객이탈예측 : 고객이 서비스를 계속 이용할 것인지 아닌지 예측
■ 다중분류는 머신러닝에서 데이터를 3 개 이상의 클래스로 나누는 작업을 의미
각 데이터 포인트가 여러 클래스 중 하나에 속하는지를 예측하는 과정.
다중분류 예시
이미지분류 : 다양한 동물(고양이,개,새 등)을 분류하는 작업.
스팸분류 : 이메일이 스팸, 일반, 홍보, 이메일 등으로 나뉘는 경우.
텍스트분류: 뉴스 기사가 정치, 스포츠, 경제 등으로 분류되는 경우.
"""
이진 분류 (Binary Classification)
정의: 두 가지 선택지 중 하나를 선택하는 문제입니다.
예시:
스팸 이메일: 이메일이 "스팸"인지 "안 스팸"인지 구분합니다.
질병 진단: 환자가 "병에 걸렸다" 또는 "병에 걸리지 않았다"는 두 가지 선택이 있습니다.
비유: 다리를 건너야 할 때, "건너기" 또는 "안 건너기"라는 두 가지 선택을 하는 것과 비슷합니다.
다중 분류 (Multi-class Classification)
정의: 세 가지 이상의 선택지 중 하나를 선택하는 문제입니다.
예시:
과일 분류: 사과, 바나나, 오렌지 중 하나를 구분합니다.
이미지 분류: 고양이, 개, 새, 토끼 등의 동물 중 하나로 분류합니다.
비유: 여러 가지 음료수 중에서 하나를 선택하는 것과 같습니다.
예를 들어, "콜라, 사이다, 주스" 중에서 선택하는 것처럼요.
간단한 정리
이진 분류: 두 가지 중 하나 (예: 스팸 vs. 비스팸)
다중 분류: 세 가지 이상 중 하나 (예: 사과 vs. 바나나 vs. 오렌지)
"""
유방암 데이터 이진분류 from sklearn.datasets import load_breast_cancer 데이터 전처리
- 데이터프레임만들어서 데이터 확인하기
- 특성에대한 스케일링(StandardScaler)
- 훈련 세트와 테스트 세트 나누기 모델학습
- 로지스틱 회귀모델 생성/학습/평가 후
- 테스트 세트 중 5개 무작위로 골라서 예측
- 예측이 맞는지 실제타겟과 비교하기
# 유방암 이진분류
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
1.데이터프레임 만들어서 데이터 확인하기.import pandas as pd
# columns :열 이름 지정하는 매개변수 = cancer.feature_names
cancer_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
cancer_df["target"] = cancer.target
# print(cancer_df)
#---------------------------------------------------------데이터 프레임만들기
2.특성에대한 스케일링(StandardScaler)
'''
from sklearn.preprocessing import StandardScaler 객체에 학습을 시킨다
'''
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(cancer.data)
input_scaled = ss.transform(cancer.data)
3. 훈련세트와 테스트세트 나누기 모델 학습
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = \
train_test_split(input_scaled, cancer.target, test_size=0.3, random_state=21)
4. 로지스틱 회귀모델 생성/ 학습/평가
# sklearn.linear_model LogisticRegression 로지스틱회귀모델
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_input, train_target)
print("훈련세트 스코어:", lr.score(train_input, train_target))
print("테스트세트 스코어:", lr.score(test_input, test_target))
5. 테스트세트 중에서 무작위로 선택해서 예측하기
# 171개중 무작위 5개 선택하기
print(len(test_input))
import numpy as np
np.arange(10) # 0부터 9까지 1차원배열만들기
np.arange(171) # 0부터 170까지 1차원배열만들기
indexes = np.arange(len(test_input))
np.random.shuffle(indexes)
print(indexes)
print(indexes[:5])
print("무작위예측:",lr.predict(test_input[indexes[:5]]))
print("실제타겟은:", test_target[indexes[:5]])
6. 예측이 맞는지 실제타겟과 비교하기
import numpy as np
indexes = np.arange(len(test_input))
np.random.shuffle(indexes)
print("무작위 예측:", lr.predict(test_input[indexes[:5]]))
print("실제 타겟은:", test_target[indexes[:5]])
훈련세트 스코어: 0.9899497487437185
테스트세트 스코어: 0.9766081871345029
171
[ 37 94 40 139 136 82 162 159 109 112 42 123 161 59 155 51 110 96 35 117 102 156 74 2 164 142 113 73 1 23 21 165 90 129 166 80 46 0 5 54 104 41 11 57 115 17 150 53 3 160 114 77 9 95 146 88 170 72 119 29 69 86 39 158 151 89 33 98 32 70 34 120 134 125 48 24 106 152 163 124 61 28 50 79 97 99 108 12 67 8 62 76 63 144 10 49 22 148 131 16 27 118 122 168 111 145 60 100 52 154 92 43 55 141 153 147 126 64 66 71 140 15 84 6 19 38 132 143 127 75 18 105 128 78 26 25 130 157 103 58 93 4 47 31 68 81 30 56 137 13 83 133 7 45 167 65 135 14 149 101 121 169 44 138 20 87 85 107 36 91 116] [ 37 94 40 139 136]
무작위예측: [0 0 1 1 0]
실제타겟은: [0 0 1 1 0]
무작위 예측: [0 0 1 1 1]
실제 타겟은: [0 0 1 1 1]
붗꽃데이터 다중분류 form sklearn.datasets import load_iris
데이터 전처리
- 데이터프레임 만들어서 데이터확인하기
- 훈련 세트와 테스트 세트 나누기
모델학습
- 로지스틱 회귀모델 생성/학습/평가 후
- 테스트 세트 중 5개 무작위로 골라서 예측
- 예측이 맞는지 실제 타겟과 비교하기
하이퍼파라미터 튜닝
- max_inter는 1000으로 고정
- C값을 다섯 개 설정하여 최적의 하이퍼 파라미터 찾기
from sklearn.datasets import load_iris
iris = load_iris()
import pandas as pd
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_df["target"] = iris.target
print(iris_df)
print(iris.target_names)
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = \
train_test_split(iris.data, iris.target, test_size=0.2, random_state=21)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_input, train_target)
print("훈련세트 스코어:", lr.score(train_input, train_target))
import numpy as np
indexes = np.arange(len(test_input))
np.random.shuffle(indexes)
print("무작위 예측:", lr.predict(test_input[indexes[:5]]))
print("실제 타겟은:", test_target[indexes[:5]])
c_list = [0.01, 0.1, 1, 10, 100]
train_score = []
test_score = []
for item in c_list :
lr = LogisticRegression(C=item, max_iter=1000)
lr.fit(train_input, train_target)
train_score.append(lr.score(train_input, train_target))
test_score.append(lr.score(test_input, test_target))
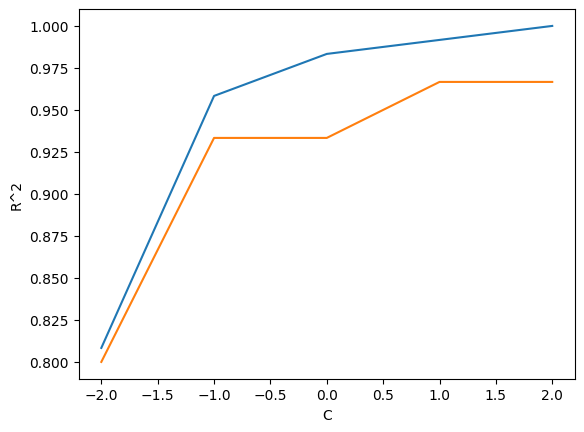
import matplotlib.pyplot as plt
plt.plot(np.log10(c_list), train_score)
plt.plot(np.log10(c_list), test_score)
plt.xlabel("C")
plt.ylabel("R^2")
plt.show() # 결론! C가 10 일 때가 그나마 낫다
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
.. ... ... ... ...
145 6.7 3.0 5.2 2.3
146 6.3 2.5 5.0 1.9
147 6.5 3.0 5.2 2.0
148 6.2 3.4 5.4 2.3
149 5.9 3.0 5.1 1.8
target
0 0
1 0
2 0
3 0
4 0
.. ...
145 2
146 2
147 2
148 2
149 2
[150 rows x 5 columns]
['setosa' 'versicolor' 'virginica']
훈련세트 스코어: 0.9833333333333333
테스트세트 스코어: 0.9333333333333333
무작위 예측: [1 0 2 1 1]
실제 타겟은: [1 0 2 1 1]
'머신러닝+딥러닝' 카테고리의 다른 글
| 머신러닝 6일차 <군집 알고리즘> .2024.10.18 (4) | 2024.10.18 |
|---|---|
| 머신러닝2일차 (연습) 몸무게와 키를 보고 여자인지 남자인지 확인해보자! (0) | 2024.10.16 |
| 머신러닝 2일차.2024.10.14. (0) | 2024.10.16 |
| 머신러닝 1일차.2024.10.10. (0) | 2024.10.10 |