비지도 학습
타깃을 모르는 비지고학습 . 타깃 X . 특성데이터만 --있는경우

print(fruits[0,0,:]
300개 데이터 100*100픽셀 흑백사진 데이터에서 0은 가장 어두운 블랙 255은 가장 밝은 흰색


fruits[0]
과일데이터의 첫번째 데이터를 이미지로 보여줌
맷플릇립의 imshow()함수를 사용하면 넘파이
배열로 저장된 이미지를 나타낼수있음.
왼쪽 사과 이미지에서 밝은부분은 0에 가깝고
짙은 부분은 255에 가까운 값이라는것을
기억 하자
# subplot 여러개 그래프 한번에 그리기 (행,열) 한줄에 2개를 그리겠다 (1,2)
fig는 matplotlib에서 생성되는 전체 그림(figure) 영역을 나타내는 객체
fig, axs = plt.subplots(1,2) # 1행 2열 서브플롯
axs[0].imshow(fruits[100], cmap = 'gray_r') # 100번째 파인애플
axs[1].imshow(fruits[200], cmap = 'gray_r') # 200번째 바나나
plt.show()

# 각 과일 이미지 배열을 1차원 형태로 변경합니다.
# reshape(-1)의 의미 -1이 사용된 위치의 차원 크기를 자동으로 계산하여 배열의 총 크기가 유지
# 즉 100개의 이미지
apple = fruits[0:100].reshape(-1, 100*100) # 0부터 99번 까지 사과 (1열 , 만개의 데이터 샘플)
pineapple = fruits[100:200].reshape(-1, 100*100) # 100부터 199번 까지 파인애플
banana = fruits[200:300].reshape(-1, 100*100) # 200에서부터 299번 까지 바나나
# 배열의크기는 (100,10000) 1차원배열로 만들기
print(apple.shape) # (100, 10000)
print(pineapple.shape) # (100, 10000)
print(banana.shape) # (100, 10000)
# 픽셀의 평균값 :

#히스토그램(통계기반 사과가 몇개있다 ) : 값이 발생한 빈도를 그래프로 표시한것.
# import numpy as np
# import matplotlib.pyplot as plt
히스토그램(histogram) :
데이터를 구간별로 나누어 각 구간에 해당하는 데이터의 빈도를 나타내는 그래프
가로축 (X축): 데이터의 구간 ,
세로축 (Y축): 각 구간에 속하는 데이터의 개수 특정 구간에 몇 개의 데이터가 속하는지 빈도
# 히스토그램 그리기
# 사과 평균 히스토그램
plt.hist(np.mean(apple, axis=1), alpha = 0.8)
plt.hist(np.mean(pineapple, axis=1), alpha = 0.8)
plt.hist(np.mean(banana, axis=1), alpha = 0.8)
# 범례추가
plt.legend(['apple','pineapple','banana'])
# 그래프 출력
plt.show()
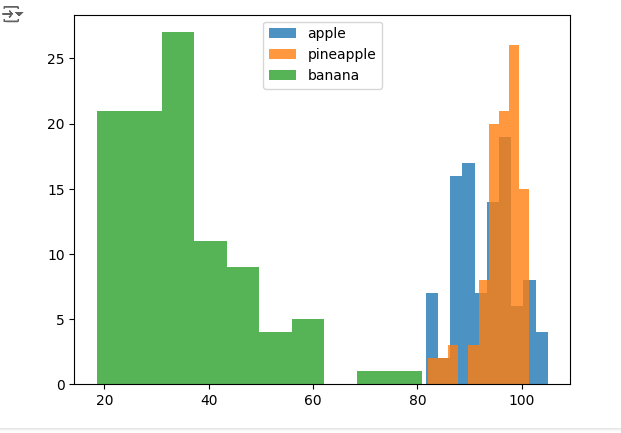
# 픽셀의 평균값을 구해보자
# import numpy as np
# import matplotlib.pyplot as plt
fig, axs = plt.subplots(1,3, figsize = (20,5))
# 1, 3은 1행 3열의 서브플롯을 생성합니다. 즉, 한 줄에 3개의 그래프를 배치합니다.
# figsize=(20, 5)는 전체 그래프의 크기를 20x5인치로 설정합니다.
# axis=0을 사용하여 각 픽셀 위치에 대한 평균값
# range(10000)은 0부터 9999까지의 범위를 생성합니다.
axs[0].bar(range(10000), np.mean(apple, axis = 0))
axs[1].bar(range(10000), np.mean(pineapple, axis = 0))
axs[2].bar(range(10000), np.mean(banana, axis = 0))
plt.show()

# 각 파일 데이터의 평균을 계산하고 100x100형태로 변환한다
# np.mean(apple, axis=0): 사과 데이터의 평균을 계산합니다. # axis=0은 각 열의 평균을 의미
# 사과의 평균 이미지
plt.show()

# 평균과 가까운 사진고르기
사과의 평균 이미지와 다른 과일들의 이미지 간의 절대 차이를 계산한 후,
# abs_mean 배열을 기준으로 인덱스를 정렬하여 가장 유사한 100개의 과일 인덱스를 선택

(100, 10000)
'머신러닝+딥러닝' 카테고리의 다른 글
| 머신러닝 이진분류 와 다중분류 유방암데이터 와 붗꽃데이터 다중분류 (7) | 2024.10.16 |
|---|---|
| 머신러닝2일차 (연습) 몸무게와 키를 보고 여자인지 남자인지 확인해보자! (0) | 2024.10.16 |
| 머신러닝 2일차.2024.10.14. (0) | 2024.10.16 |
| 머신러닝 1일차.2024.10.10. (0) | 2024.10.10 |